
You Mengzhe
2020年12月8日星期二
K8S健康检查最佳实践
我们都知道分布式系统非常难以管理,很大的一个原因是要是整个系统的可用性,是需要所有的部件(服务)都正常工作。如果一个小的部件不可用,系统应该可以检测到,绕过该部件,然后修复它,而且这样的行为应该可以自动进行。
健康检查就是一个简单方法,使系统可以知道应用(服务)的一个实例是否正常工作。如果一个实例能正常工作,那其他服务不应该访问它或者向它发送请求,请求应该发送到健康的实例。而系统应该恢复应用的监控状态。
当我们使用 Kubernetes 来运行和管理我们的应用(服务),默认情况下当一个Pod里的所有容器都启动后,就向该Pod发送相应的流量,并且当容器崩溃的时候重启容器。在一般情况下,这个行为也是可以接受的,不过k8s还提供了对容器的健康检查机制,可以让我们的部署更加健壮。
在演示如何具体配置K8S的健康检查之前,让我们来看看什么健康探测模式(Health Probe Pattern)?
健康探测模式
当我们设计一个关键任务,高可用的应用时,弹性是我们需要考虑的最重要方面之一。当一个应用能快速从失败中恢复,那个这个应用就是具有弹性的。
为了保证基于k8s部署的应用是高可用的,在设计集群时,我们需要遵从特定的设计模式。而健康探测就是其中的一种模式,它定义了应用如何向系统(k8s)报告它自己的健康状态。
这里所谓的健康状态不仅仅是Pod是否启动及运行,还应包括其是否可以正常处理请求并响应,这样k8s就可以更加合理地进行流量路由以及负载均衡。
Kubernetes的健康探测
我们都知道,k8s通过各种控制器对象(Deployment, StatefulSets等)来监控Pod的状态,如果一个控制器检测到Pod由于某些原因崩溃,它就会尝试重新启动Pod,或者把Pod调度到其他节点上进行启动。然而,Pod是可以报告自己的状态的,例如一个使用Nginx作为web服务器的应用,通过Deployment部署到集群里并正常启动,这个时候检测到Pod的的状态是运行着的,但是可能由于某些原因导致访问web服务时确返回500(内部服务错误),对请求者来说该服务是不可用的状态。
默认情况下,k8s的kubelet继续地探测容器的进程,当探测到进程退出,它会重启容器的Pod,有些情况下重启可以让容器恢复正常。但像上面的例子,容器的进行正常运行,而应用却返回500错误,并不能正确地探测到应用的健康状态。
因此,k8s提供了两个类型的探测: 存活探测(Liveness Probe),就绪探测(Readiness Probe)。
存活探测(Liveness Probe)
很多应用在长时间运行,或者遇到某种错误进入死锁状态,除非重启,否则无法恢复。因此k8s提供存活探测(Liveness Probe)来发现并恢复这种状态,当然存活探测检查到错误时,kubelet将对Pod采取重启操作来恢复应用
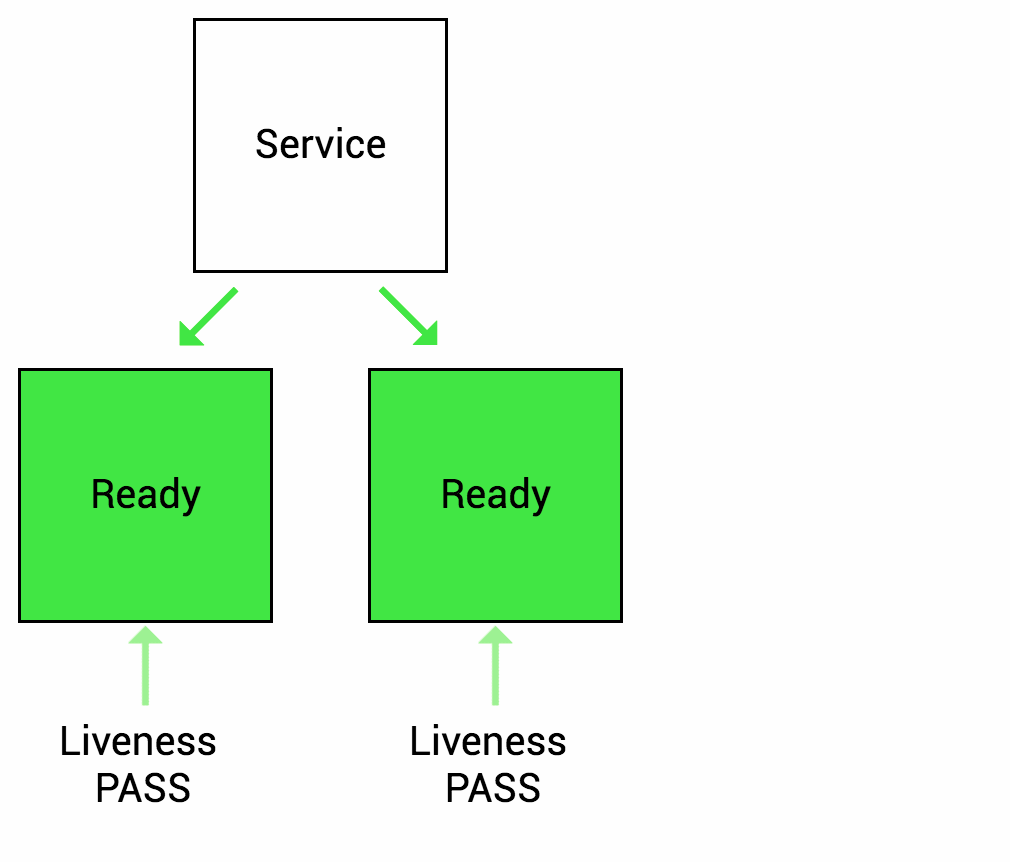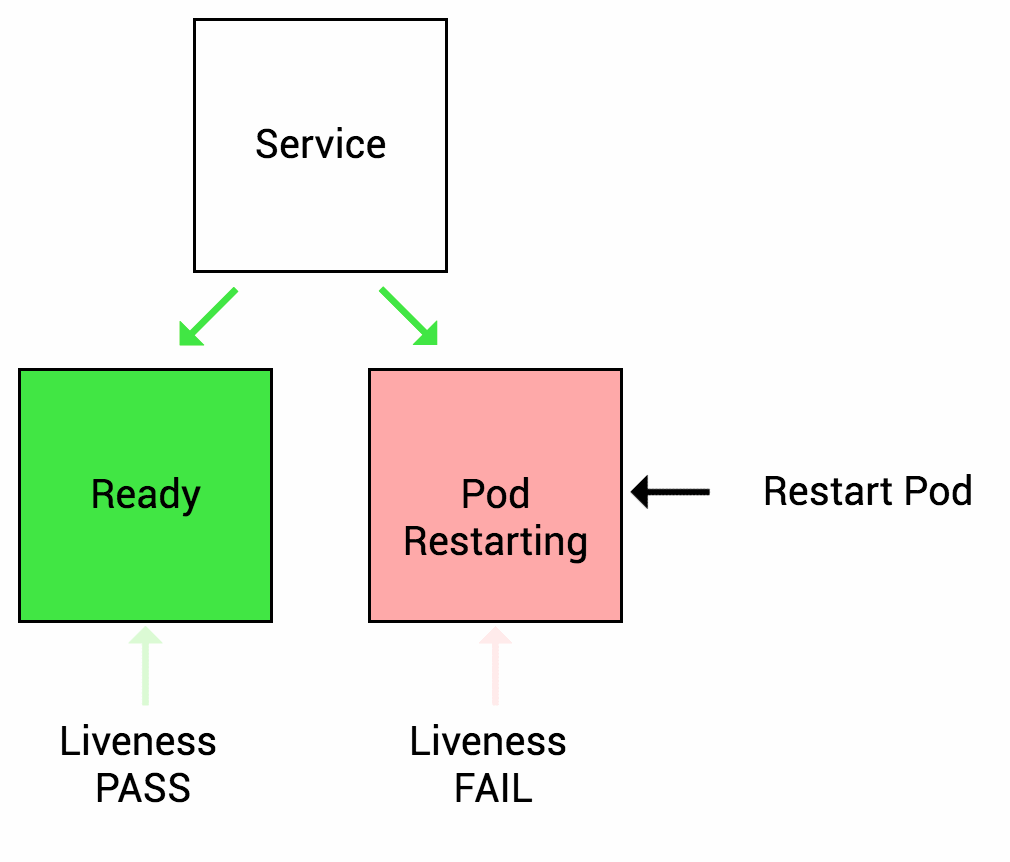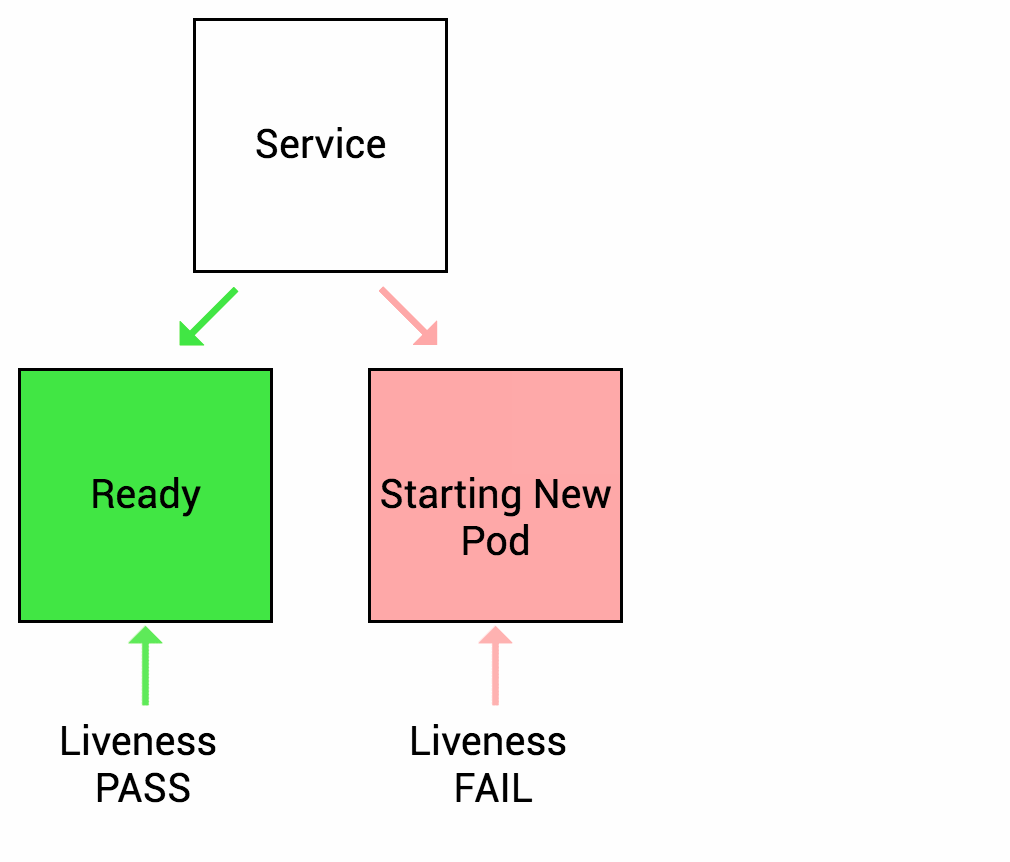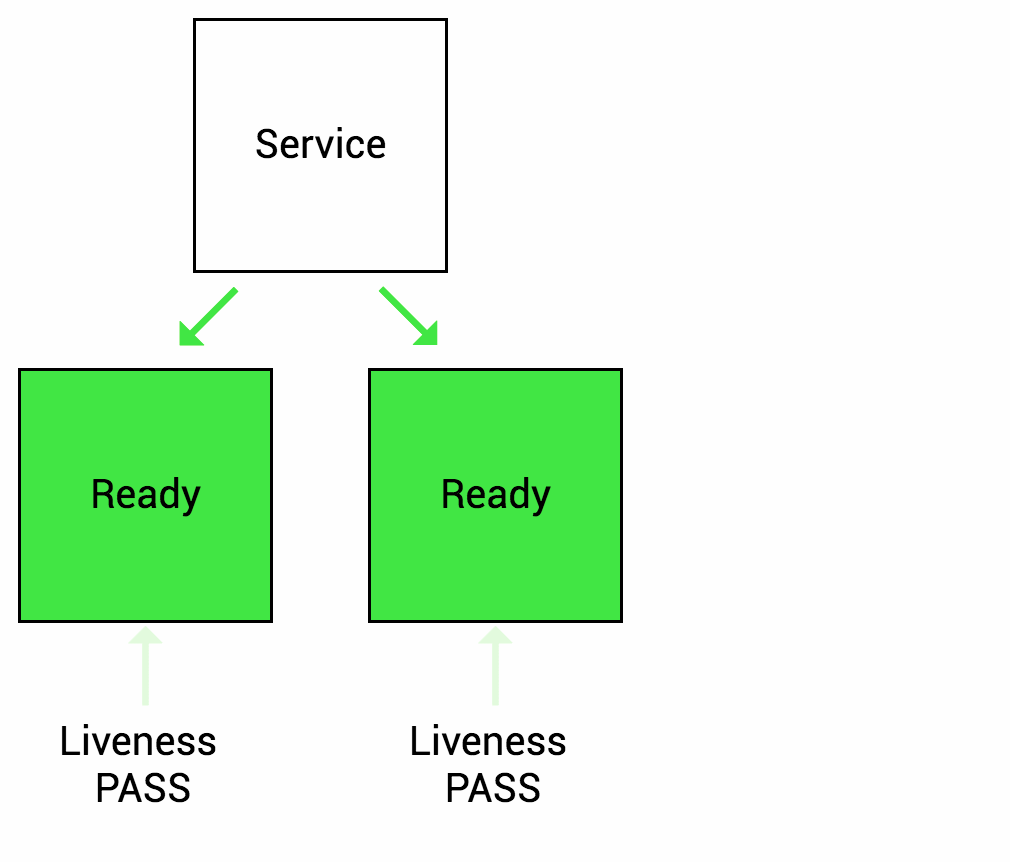
就绪探测(Readiness Probe)
有时应用会暂时性的不能对外提供网络服务,例如在负载比较大的是偶,或者在应用启动的时候可能需要加载大量数据或做一些初始化的动作,需要一定时间来准备对外提供服务。
这样的情况下,系统探测到应用实例不可用时,不应该杀死应用重启,而是应该分配流量,不往该实例发送请求(通过配置服务负载)。
因此,k8s提供了就绪探测来发现并处理这种情况,发现Pod里的容器为就绪时,会设置应用的service(k8s资源对行)移除该实例的Endpoint(服务端点),使得流量然过该不可用的服务实例,等待探测起就绪后,再将其端点添加回相应的服务。当然如果应用是第一次启动,则会等待就绪探测成功后才会将其添加到服务端点。
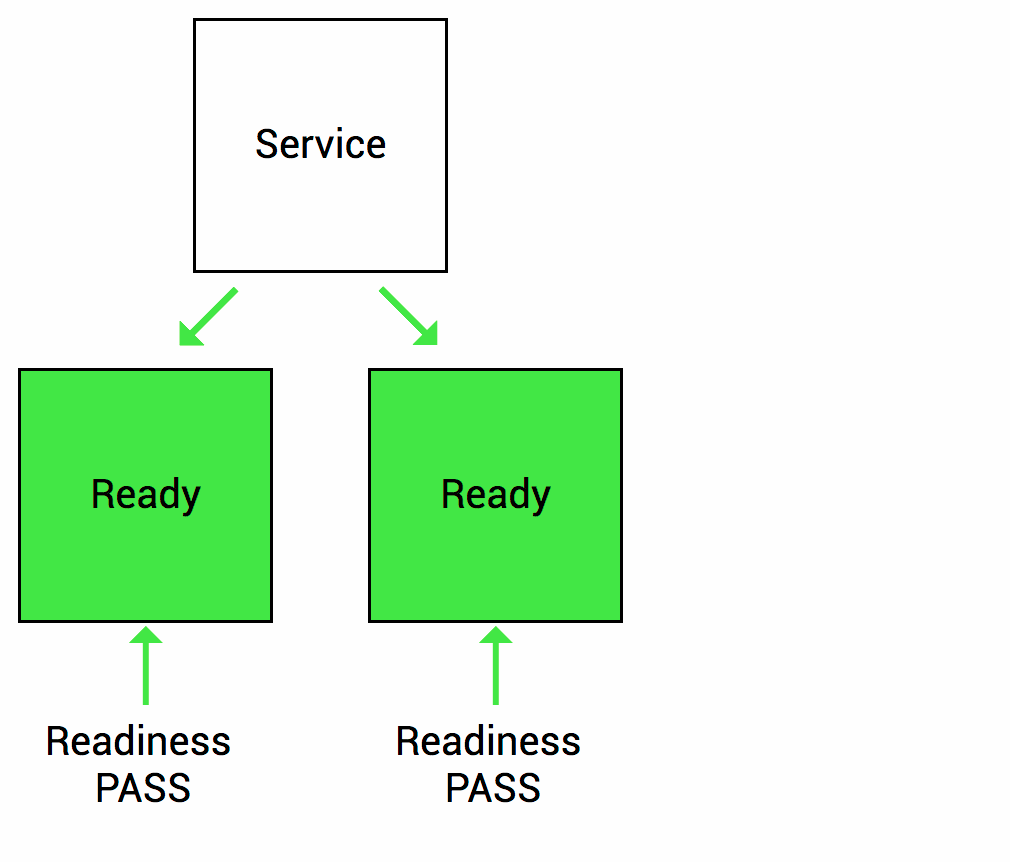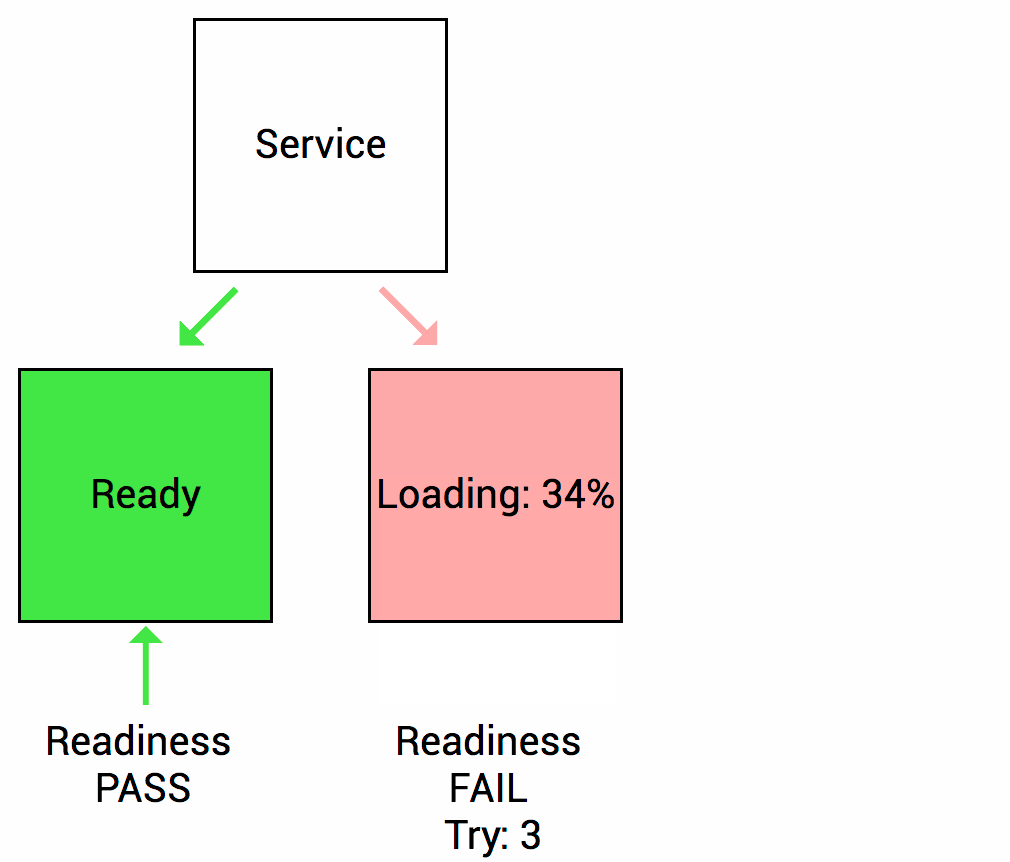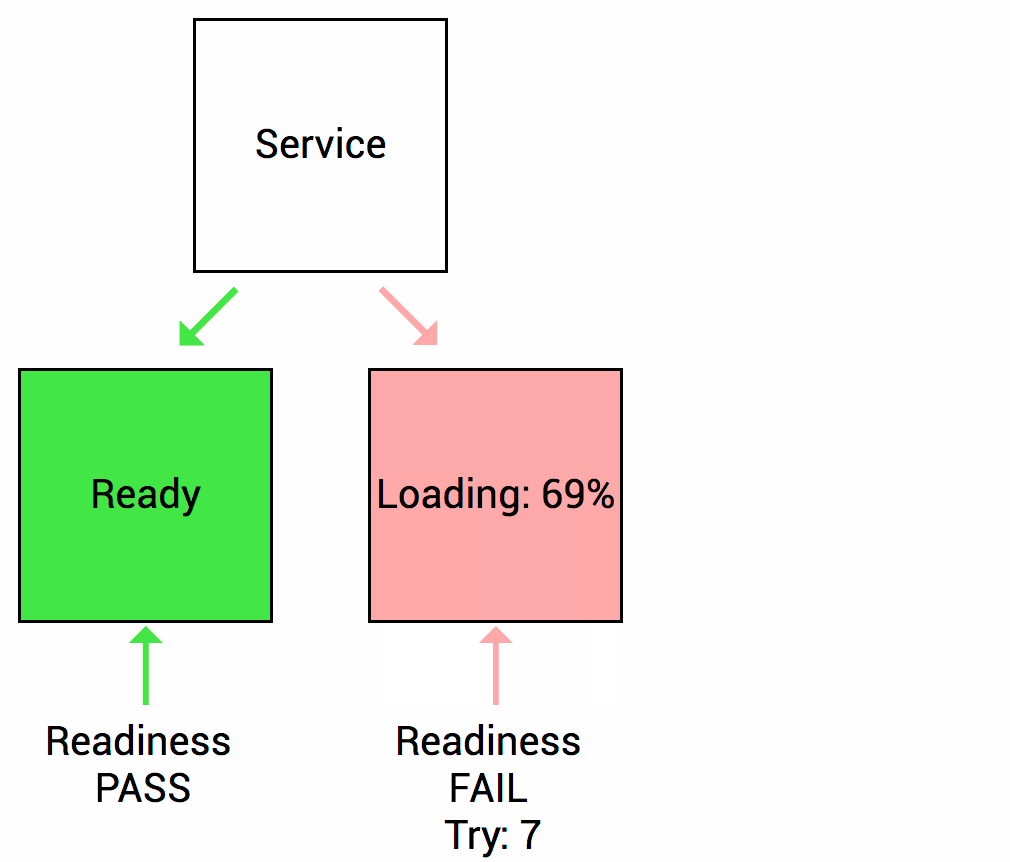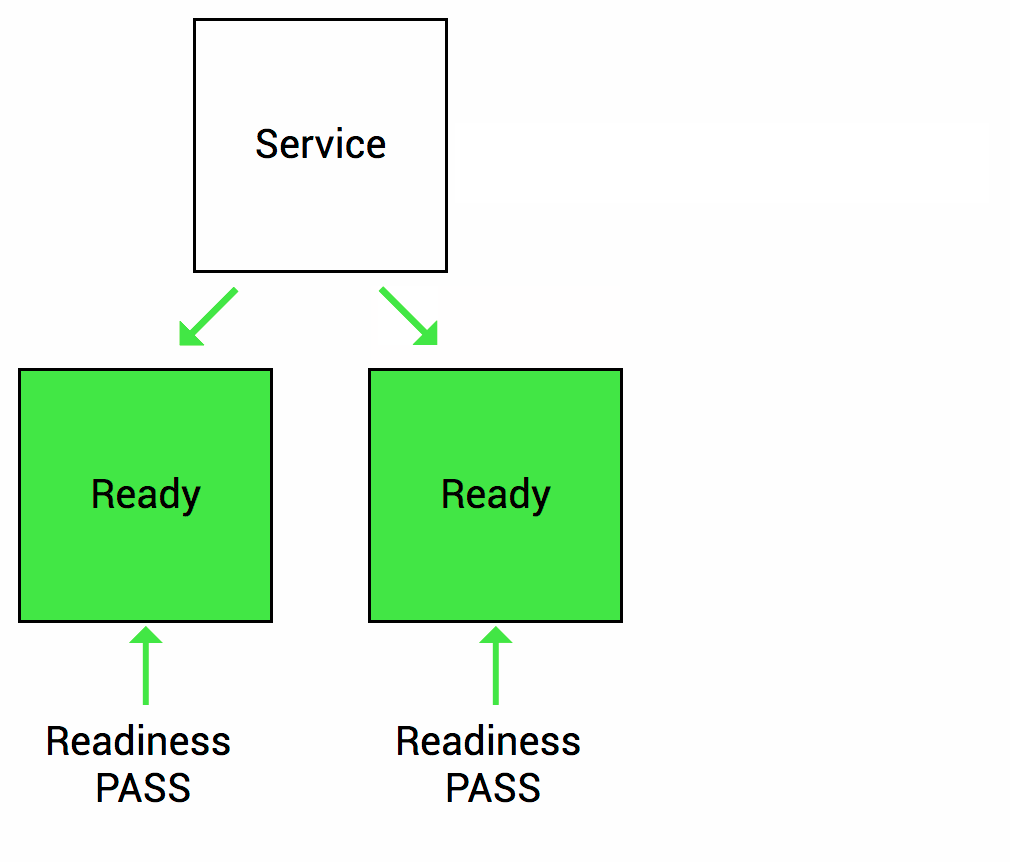
Kubernetes探测方法
那系统如何来探测容器的健康状态呢?k8s支持配置三种探测方法: 执行命令,TCP,HTTP 。
三种方法都可以应用到存活和就绪探测。
执行命令
通过在容器内执行命令来判断容器的状态,如果命令返回值为 0,则认为容器是健康的;如果返回值为非 0,则认为容器是不健康的。
这种方式一般在容器运行的应用没有提供HTTP的服务,也没有任何TCP端口启动来提供服务的情况,而可以通过运行一个命令来确定应用是否健康。
下面是配置一个Pod使用命令
apiVersion: v1
kind: Pod
metadata:
name: app
spec:
containers:
- image: example/app:v1
name: app
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
上面的示例就使用命令 cat /tmp/healthy 来进行存货探测,如果容器里不存在 /tmp/healthy 文件,则命令返回非0值,k8s则认为容器不健康,这里使用了存活探测,因此会重启该Pod。
TCP
那TCP方式,就是通过尝试向容器监听的端口建立TCP连接来确定其是否健康,如果能成功建立连接,则认为健康,否则不健康。
apiVersion: v1
kind: Pod
metadata:
name: app
spec:
containers:
- image: example/app:v1
name: app
ports:
- containerPort: 3000
protocol: TCP
livenessProbe:
tcpSocket:
port: 3000
initialDelaySeconds: 15
periodSeconds: 20
上面示例了通过配置TCP方式的存活探测,k8s会通过检查Pod端口3000来确认容器是否健康,上面的配置中有两个参数:
- initialDelaySeconds - Pod启动时等待多少时间(15秒)后开始进行检查,该参数用于应用需要一定时间启动的情况,避免一开始就检查失败而导致Pod重启
- periodSeconds - 进行端口检查的周期时间,也就是在Pod运行时,每20秒进行一次检查
HTTP
如果应用是一个HTTP服务(或者实现了一个HTTP服务的API来报告健康状态),则可以通过配置HTTP的方式来进行探测
apiVersion: v1
kind: Pod
metadata:
name: app
spec:
containers:
- image: exmaple/app:v1
name: app
ports:
- containerPort: 8080
protocol: TCP
livenessProbe:
httpGet:
path: /
port: 3000
initialDelaySeconds: 5
periodSeconds: 20
HTTP方式通过向容器的端口和指定路径发送http请求,如果请求的返回值是 200 - 300 之间,则认为是成功的,如果返回值为其他值,例如500,则认为是失败的。
健康探测还可以配置更多参数来做判定,详细信息可参考 Kubernetes文档 。
总结
在云原生应用之前,主要通过应用日志来监控和分析应用的健康状态,然而当应用不可用时没有什么方法来自动恢复应用。当然日志依然非常有用的,应次也需要日志聚合系统来收集所有应用的日志进行观测和分析应用程序行为。
对于分布式系统,以及基于容器的微服务架构云原生应用,我们需要更加快速地将应用从失败中恢复,保证系统的健壮性。因此在进行应用设计的时候,我们应该考虑合适的健康探测模式,在通过Kubernetes进行应用编排的时候,也要尽可能地对容器进行健康状态的探测,是的k8s在发现应用实例不可用的时候,采取保证系统高可用的操作。
参考: